Exploratory Data Analysis
What the catalog actually looks like
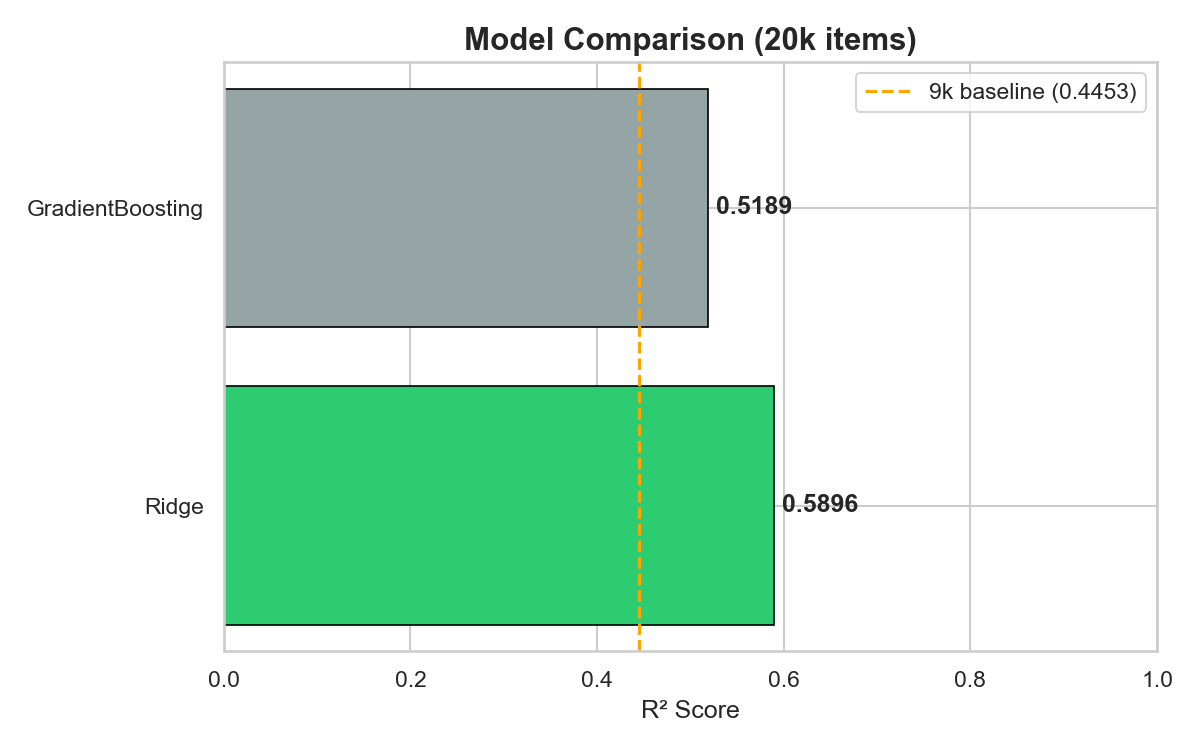
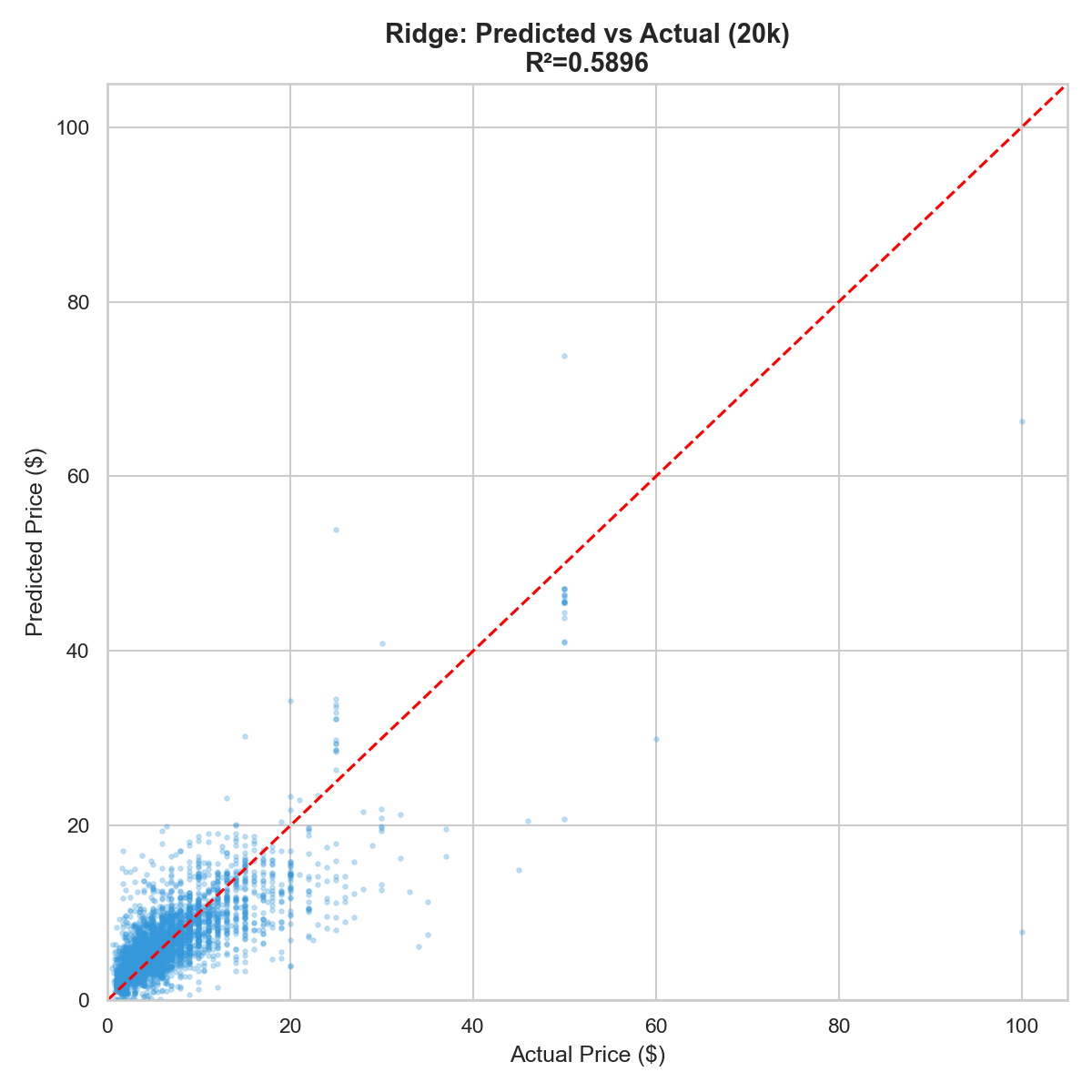
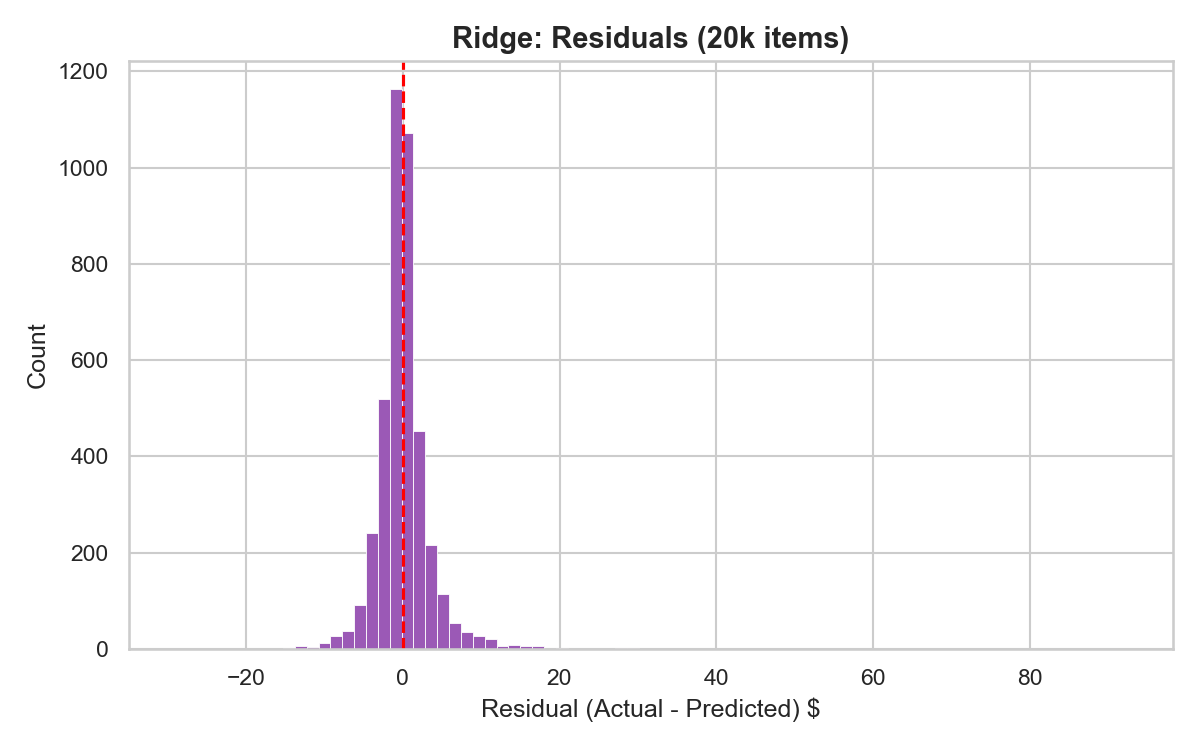
Three angles on the data: shelf-space allocation by category, price variance within categories, and which aisles King Kullen discounts most aggressively.
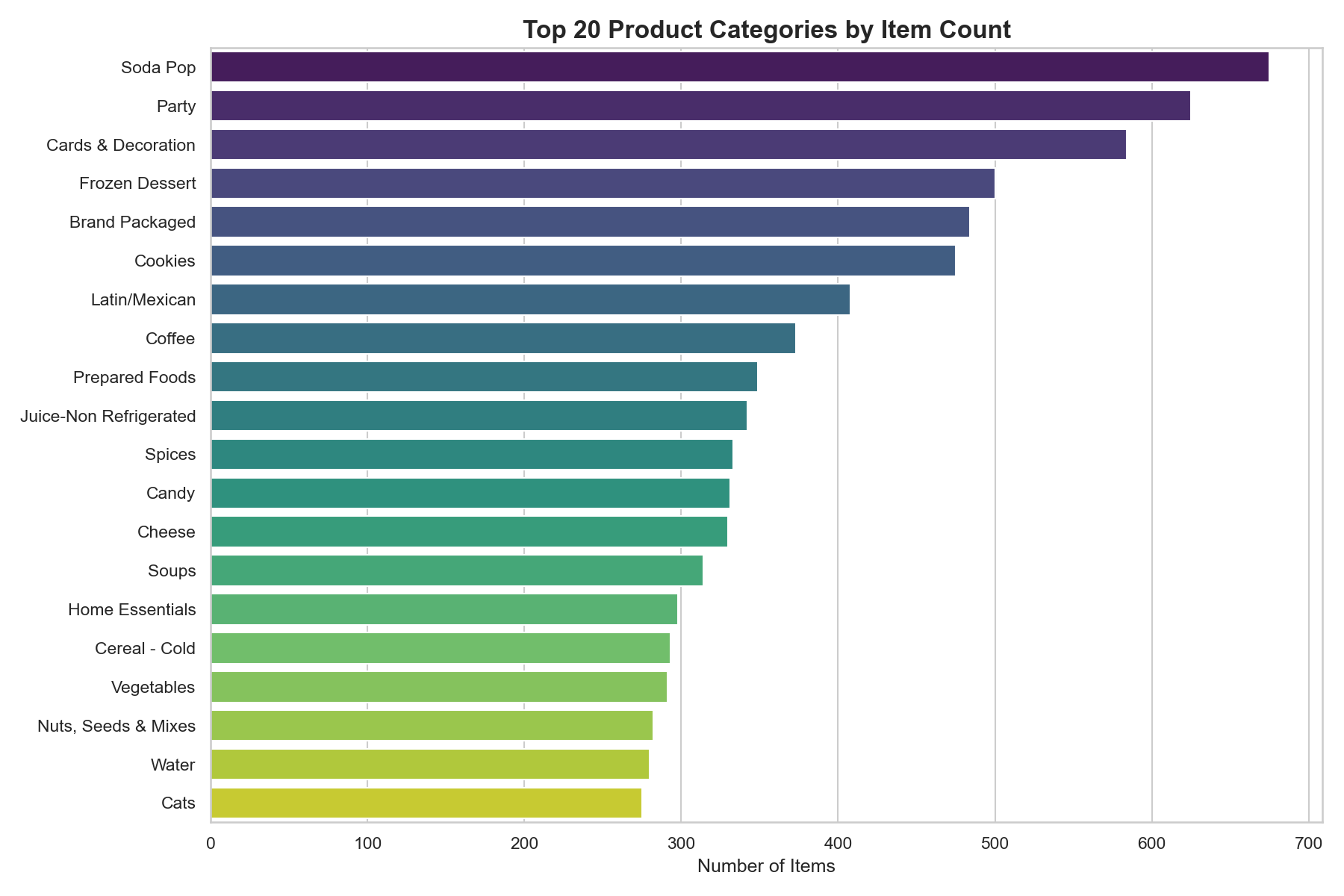
Shelf space by category
The 20 most-populated sub-categories by item count. Pantry staples and broad beverage categories dominate the catalog. This asymmetry will be the largest source of model bias in early training runs.
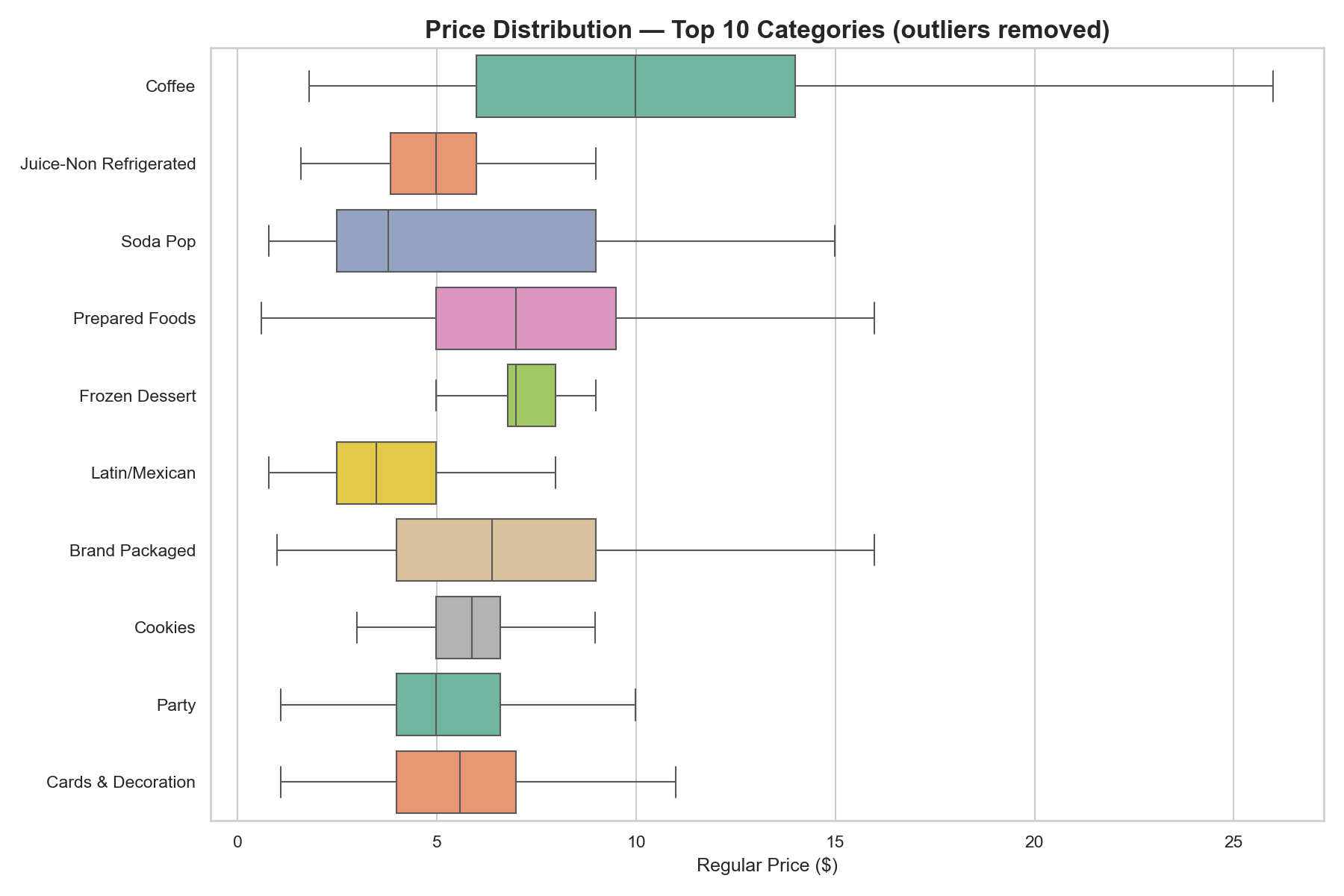
Price spread per category
Boxplots for the 10 most-populated categories. Wide interquartile ranges signal a mix of generic and premium SKUs in the same aisle. Narrow boxes signal commodity sections where price competition has compressed the range.
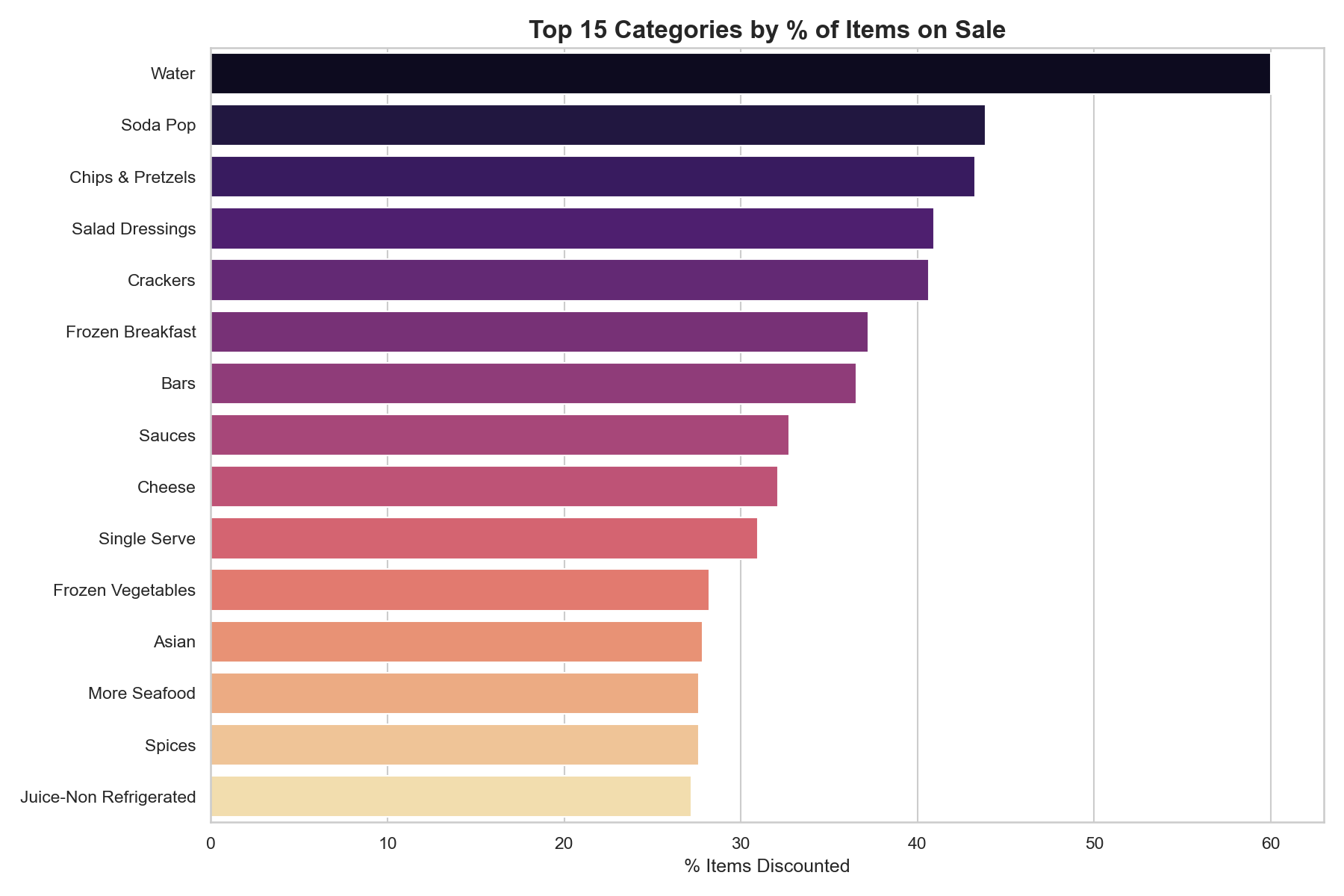
Which aisles run the deepest deals
Categories with the highest proportion of items currently on sale, filtered to categories with 50 or more products. These are the aisles where promotional cadence is the strongest pricing signal.
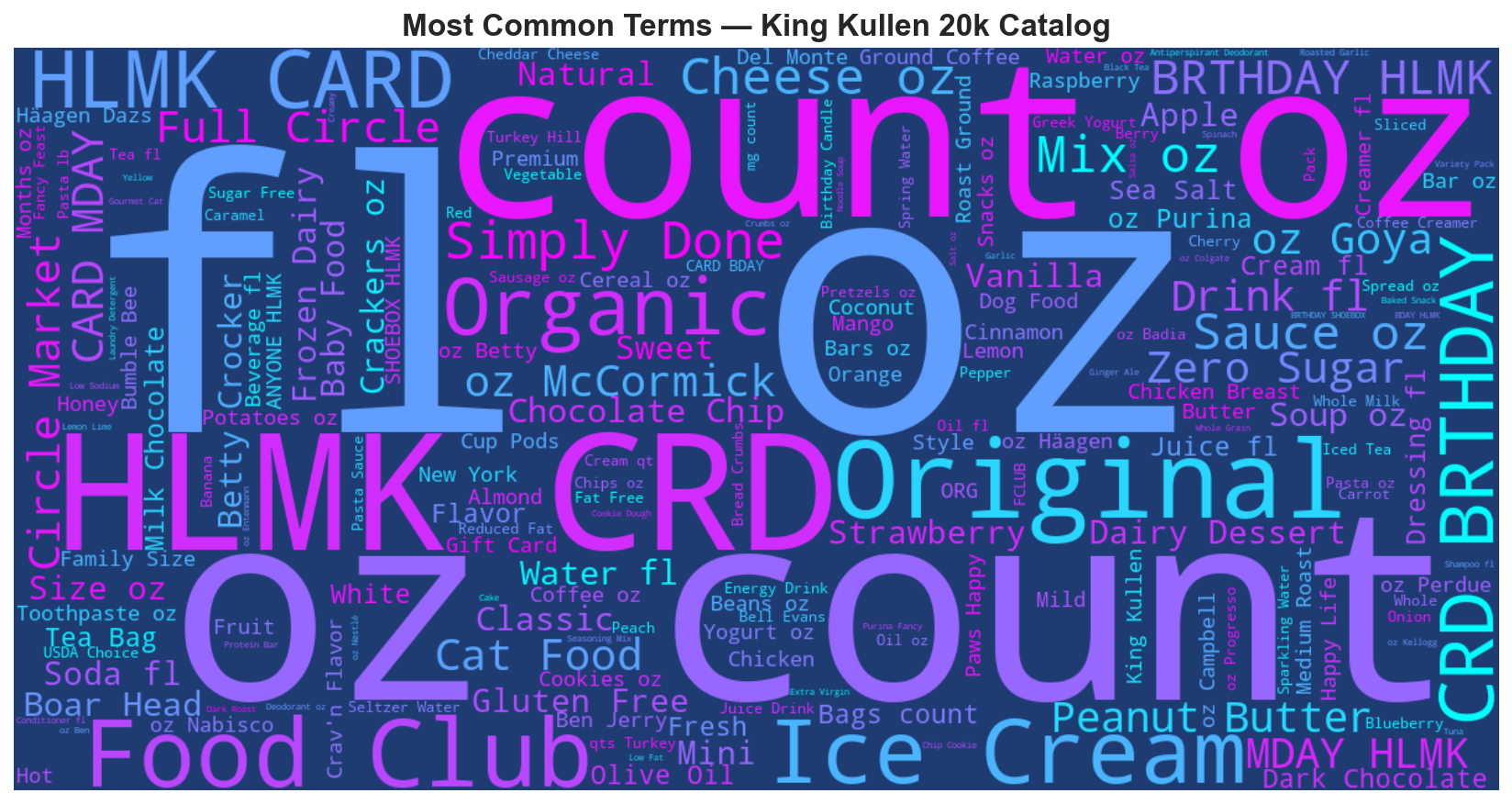
The language of the catalog
Word cloud built from 9,834 product names. High-frequency terms like "organic," "oz," and brand names dominate. These are the raw materials for the TF-IDF feature layer in the Ridge regression model.